
When talking about Big Data, one initiative is worth a mention – The Google Ngrams . Google, in its on magnanimous way, started an program to digitize every single printed document, within the copyright limits back, in 2004. Started as a partnership with some of the well-known libraries around the globe such as the New York Public Library, the Harvard University Library and
Bodleian Library at University of Oxford , the plan was to make high resolution digital images of all printed documents – books magazines et al – and save them in a huge repository that is searchable through books.google. com.
As the collection grew, Google realized the potential to actually digitize them one word at a time. Through a tool known as reCAPTCHA they then started to extract every word from every single image that was scanned. What was born out of it was an amazingly large data set from words dating back to 1500. By 2012, they had almost 15% of all the printed books digitized and that amounted to almost 700 billion words! What came out of this was Google Ngrams !
An “ngram” is a sequence of letters of any length, which could be a word, a misspelling, a phrase or gibberish
Google Ngrams is a searchable word repository, which graphs the occurrence of a word or a phrase in a “corpus of books” (as Google themselves puts it). It then plots those occurrences across time and the result is a visualization of how frequent the words were used over time.
As curious as I was, I decided to try out a few of the “jargons” of today to see how far back it was used. The results were alarming!
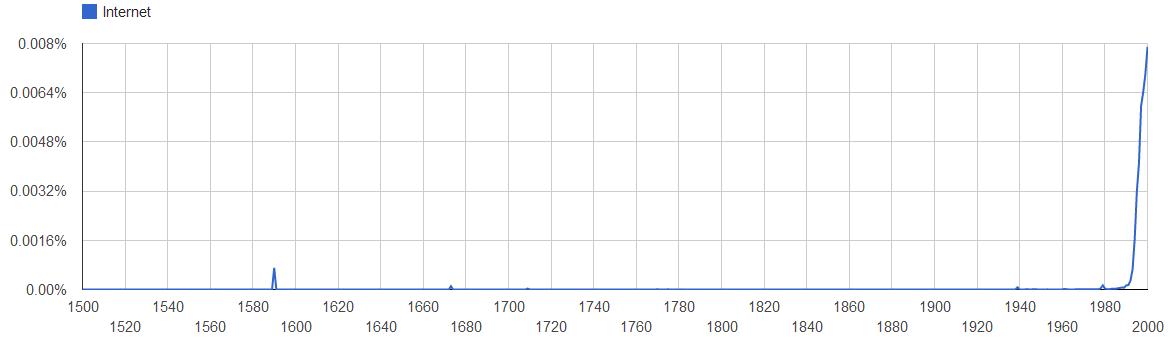
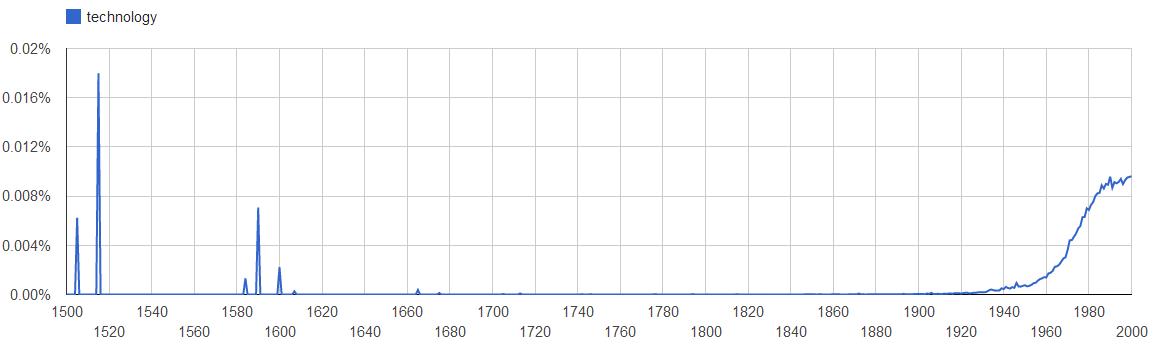
The word “technology” (keep in mind the search is case sensitive) was used as long back as early 1500s, which is ok considering it is quite a defined term in the English dictionary. But what was even more puzzling is that the word “Internet” was used in the 1590s! Now what can that be referred to! Also, although the whole slew of ARPANET and packet switching started to evolve in the 1960s it wasn’t until 1990s when the word “Internet” started to be used widely in printed form!


